2020-11-0x02
Keywords: Python leancloud ABAP
Share¶
leancloud 薪酬体系¶
ABAP OO 教程¶
关于 Python 导入的小故事  ¶
¶
https://github.com/piglei/one-python-craftsman/blob/master/zh_CN/9-a-story-on-cyclic-imports.md
之前关于我对 Python 模块管理的一大疑惑
Tools¶
Web Framework Benchmarks¶
Pyhton web 框架对比
Code Snippets¶
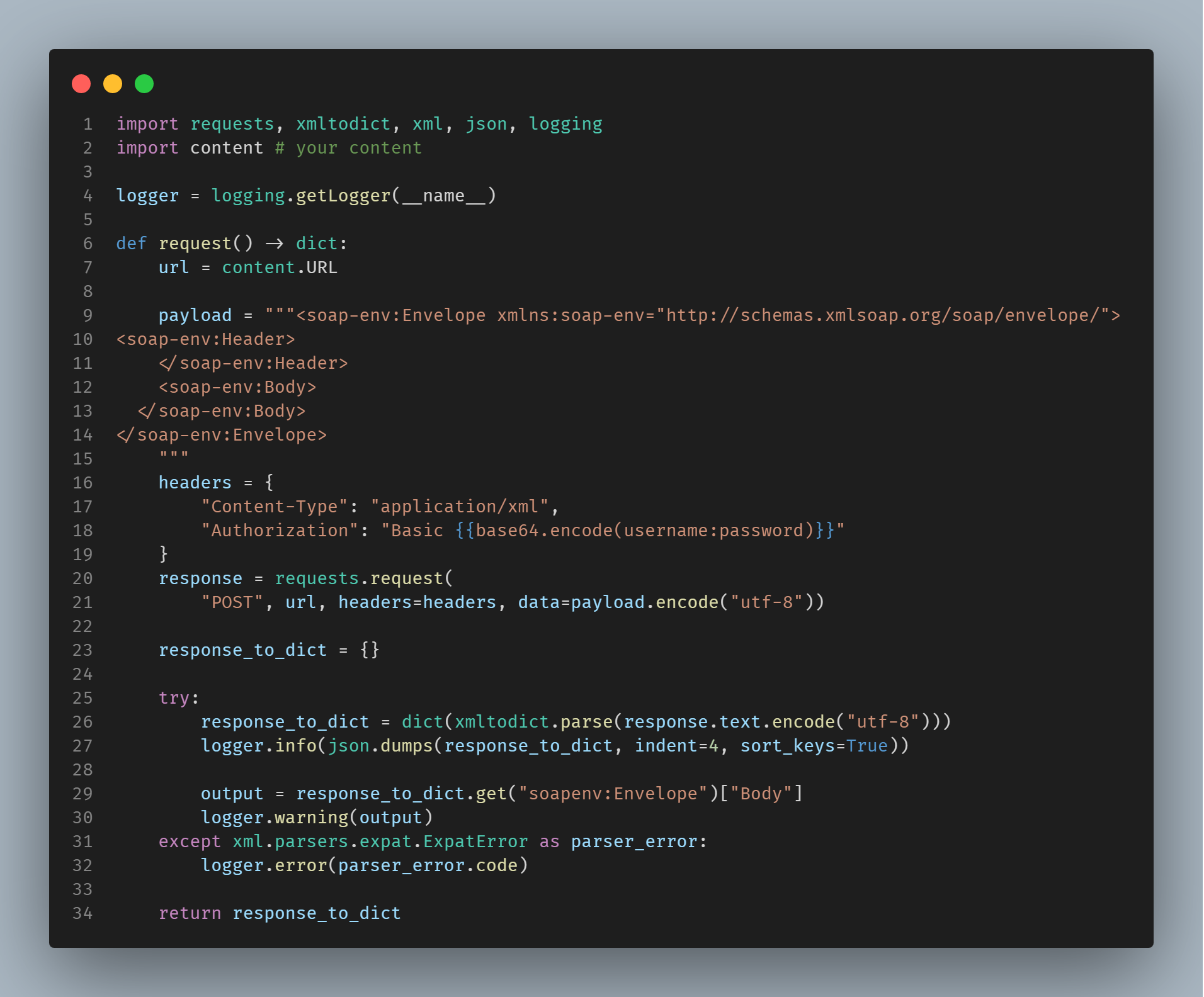


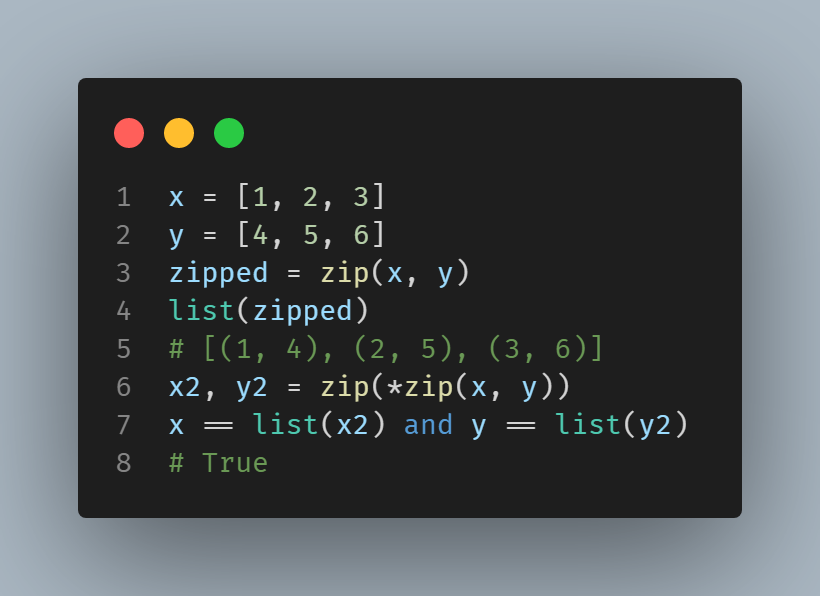
Note¶
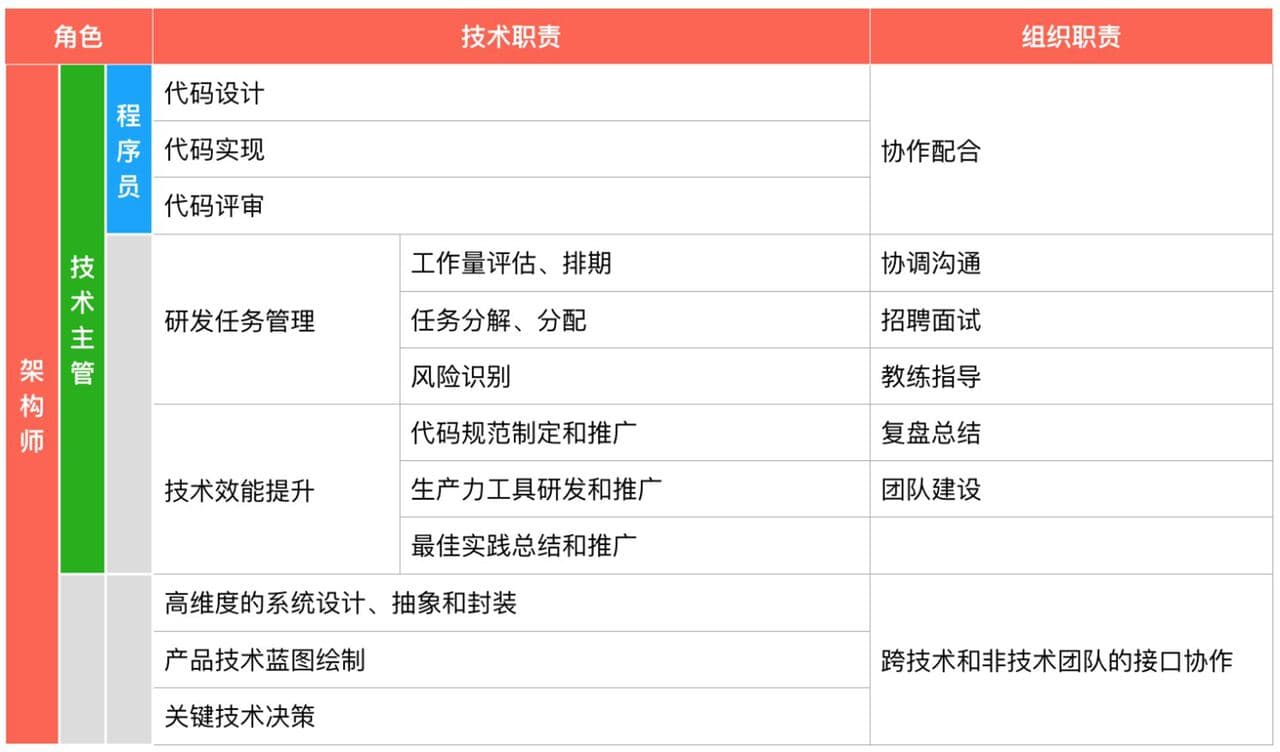
团队职责¶
来源网络
one-python-craftsman¶
https://github.com/piglei/one-python-craftsman/blob/master/zh_CN/10-a-good-player-know-the-rules.mds
- 定义了 str 方法的对象,就可以使用 str() 函数来返回可读名称
- 定义了 next 和 iter 方法的对象,就可以被循环迭代
- 定义了 bool 方法的对象,在进行布尔判断时就会使用自定义的逻辑
使用 dataclass 简化代码 故事到这里并没有结束。在上面的代码里,我们手动定义了自己的 数据类 VisitRecord,实现了 init、eq 等初始化方法。但其实还有更简单的做法。
因为定义数据类这种需求在 Python 中实在太常见了,所以在 3.7 版本中,标准库中新增了 dataclasses 模块,专门帮你简化这类工作。
如果使用 dataclasses 提供的特性,我们的代码可以最终简化成下面这样:
@dataclass(unsafe_hash=True)
class VisitRecordDC:
first_name: str
last_name: str
phone_number: str
# 跳过「访问时间」字段,不作为任何对比条件
date_visited: str = field(hash=False, compare=False)
def find_potential_customers_v4():
return set(VisitRecordDC(**r) for r in users_visited_phuket) - \
set(VisitRecordDC(**r) for r in users_visited_nz)
不用干任何脏活累活,只要不到十行代码就完成了工作。
class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def __format__(self, format_spec):
if format_spec == 'long':
return f'{self.name} is {self.age} years old.'
elif format_spec == 'simple':
return f'{self.name}({self.age})'
raise ValueError('invalid format spec')
piglei = Student('piglei', '18')
print('{0:simple}'.format(piglei))
print('{0:long}'.format(piglei))
让我们看看,上面的代码一共用到了哪些与文件处理相关的函数:
os.listdir(path):列出 path 目录下的所有文件*(含文件夹)*
os.path.splitext(filename):切分文件名里面的基础名称和后缀部分
os.path.join(path, filename):组合需要操作的文件名为绝对路径
os.rename(...):重命名某个文件
使用 pathlib 模块改写代码 为了让文件处理变得更简单,Python 在 3.4 版本引入了一个新的标准库模块:pathlib。它基于面向对象思想设计,封装了非常多与文件操作相关的功能。如果使用它来改写上面的代码,结果会大不相同。
使用 pathlib 模块后的代码:
from pathlib import Path
def unify_ext_with_pathlib(path):
for fpath in Path(path).glob('*.txt'):
fpath.rename(fpath.with_suffix('.csv'))
和旧代码相比,新函数只需要两行代码就完成了工作。而这两行代码主要做了这么几件事:
首先使用 Path(path) 将字符串路径转换为 Path 对象 调用 .glob('*.txt') 对路径下所有内容进行模式匹配并以生成器方式返回,结果仍然是 Path 对象,所以我们可以接着做后面的操作 使用 .with_suffix('.csv') 直接获取使用新后缀名的文件全路径 调用 .rename(target) 完成重命名 相比 os 和 os.path,引入 pathlib 模块后的代码明显更精简,也更有整体统一感。所有文件相关的操作都是一站式完成。
其他用法 除此之外,pathlib 模块还提供了很多有趣的用法。比如使用 / 运算符来组合文件路径:
# 😑 旧朋友:使用 os.path 模块
>>> import os.path
>>> os.path.join('/tmp', 'foo.txt')
'/tmp/foo.txt'
# ✨ 新潮流:使用 / 运算符
>>> from pathlib import Path
>>> Path('/tmp') / 'foo.txt'
PosixPath('/tmp/foo.txt')
或者使用 .read_text() 来快速读取文件内容:
# 标准做法,使用 with open(...) 打开文件
>>> with open('foo.txt') as file:
... print(file.read())
...
foo
# 使用 pathlib 可以让这件事情变得更简单
>>> from pathlib import Path
>>> print(Path('foo.txt').read_text())
foo
除了我在文章里介绍的这些,pathlib 模块还提供了非常多有用的方法,强烈建议去 官方文档 详细了解一下。
如果上面这些都不足以让你动心,那么我再多给你一个使用 pathlib 的理由:PEP-519 里定义了一个专门用于「文件路径」的新对象协议,这意味着从该 PEP 生效后的 Python 3.6 版本起,pathlib 里的 Path 对象,可以和以前绝大多数只接受字符串路径的标准库函数兼容使用:
>>> p = Path('/tmp')
# 可以直接对 Path 类型对象 p 进行 join
>>> os.path.join(p, 'foo.txt')
'/tmp/foo.txt'
所以,无需犹豫,赶紧把 pathlib 模块用起来吧。
使用 callable 可以检测某个对象是否「可被调用」
它还会引诱你不断往阵内塞入越来越多的代码,包括过滤掉无效元素、预处理数据、打印日志等等。甚至一些原本不属于同一抽象的内容,也会被塞入到同一片黑魔法阵内。
但是在 Python 3.5 以后的版本,你可以直接用 ** 运算符来快速完成字典的合并操作:
user = {**{"name": "piglei"}, **{"movies": ["Fight Club"]}}
19:00
创建日期: 2020-11-10